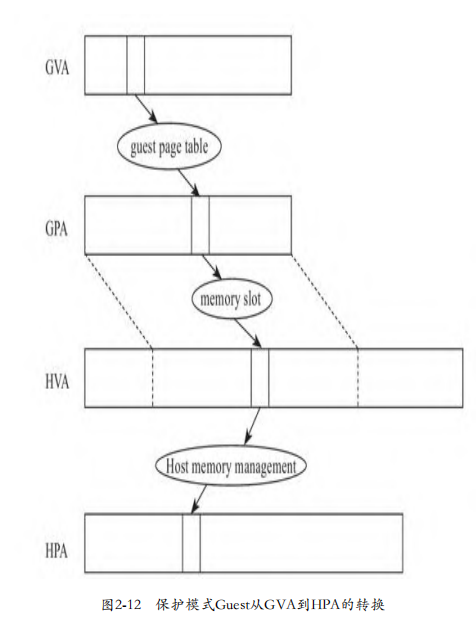
一、保护模式Guest的寻址 原理 为每个guest进程分别制作一张表,记录着GVA到HPA的映射关系。guest模式下的cr3寄存器不再指向内部GVA到GPA映射的表,而是指向这张新的表。 当MMU收到GVA时,通过遍历这张新的表,将GVA翻译成HPA。
因为guest自身页表不能完成GVA到HPA的多层地址映射,因此每当guest设置cr3寄存器时,KVM都需要截获这个操作,将cr3替换为影子页表 ,因此每次设置cr3时都需要触发虚拟机退出,陷入KVM模块。(无疑会造成很大的资源消耗,有EPT之后就不用了)
两个关键点:
KVM需要构建GVA映射到HPA的页表,这个页表需要根据guest内部页表的信息更新 ,实际地址映射时生效的是这张页表,会将guest内部的页表给隐藏起来,所以它叫影子页表
保护模式的guest有自己的页表,而且不只有一个页表,每个任务都会有自己的页表,随着任务的切换而更换页表 ,所以,KVM也需要准备多个影子页表,每个guest任务对应一个。 并且在guest内部任务切换时,kvm需要捕获这个切换,切换对应的影子页表。
建立映射时,需要经过三次转换:
第一次是guest使用自身的页表完成GVA到GPA的转换
第二次是KVM根据内存条信息完成GPA到HVA的转换
第三次是host利用内核的内存管理机制完成HVA到HPA的转换
影子页表构建好后,在映射建立完成后,GVA到HPA经过一次映射即可。
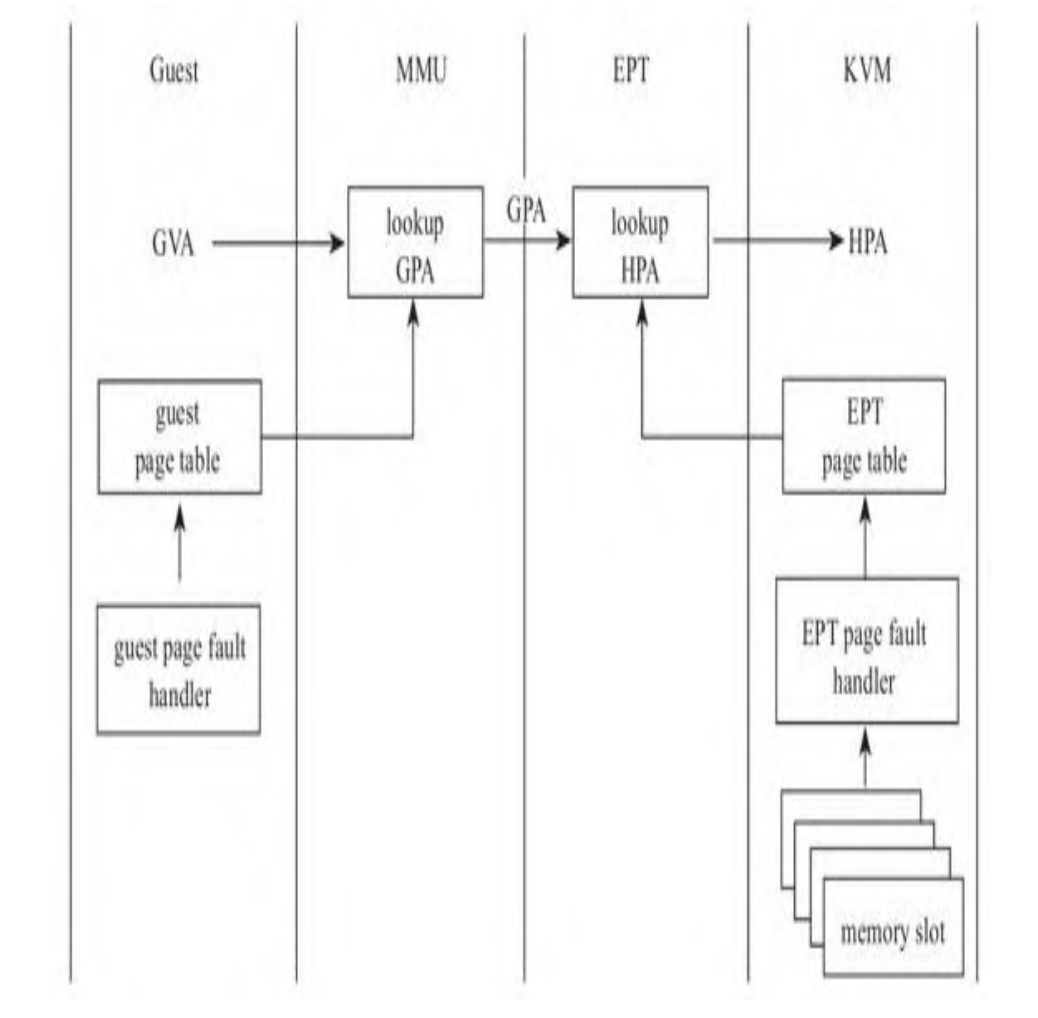
影子页表的建立 / 缺页异常处理 保护模式guest发生缺页异常时,控制cr2寄存器中存储的是GVA,而只有guest知道GVA到GPA的映射,所以,缺页异常处理函数首先需要遍历guest的页表,取出对应的GPA。
如果没有建立GVA到GPA的映射,则KVM向guest注入缺页异常 ,guest进行正常的缺页异常处理,完成GVA到GPA的映射。建立好GVA到GPA的映射后,然后再继续建立GVA到HPA的映射。
刚开始时,影子页表是空的,所以开始时任何内存访问操作都会引起缺页异常,导致vm exit 进入handle_exception_nmi (不可屏蔽中断异常处理)
handle_exception_nmi从这里进入异常处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static int handle_exception_nmi (struct kvm_vcpu *vcpu) { struct vcpu_vmx *vmx = struct kvm_run *kvm_run = ...... if (is_page_fault(intr_info)) { cr2 = vmx_get_exit_qual(vcpu); if (enable_ept && !vcpu->arch.apf.host_apf_flags) { WARN_ON_ONCE(!allow_smaller_maxphyaddr); kvm_fixup_and_inject_pf_error(vcpu, cr2, error_code); return 1 ; } else return kvm_handle_page_fault(vcpu, error_code, cr2, NULL , 0 ); }
调用链如下
1 2 3 4 - kvm_handle_page_fault - kvm_mmu_page_fault - kvm_mmu_do_page_fault -
到了这里之后, 如果没开启ept,会进入else,猜测这里的page_fault是FNAME(page_fault),这样就连起来了
1 2 3 4 5 6 7 8 static inline int kvm_mmu_do_page_fault (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u32 err, bool prefetch, int *emulation_type) { ..... if (IS_ENABLED(CONFIG_RETPOLINE) && fault.is_tdp) r = kvm_tdp_page_fault(vcpu, &fault); else r = vcpu->arch.mmu->page_fault(vcpu, &fault);
GVA-GPA 映射 kvm\mmu\paging_tmpl.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static int FNAME (page_fault) (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) { struct guest_walker walker ; int r; pgprintk("%s: addr %lx err %x\n" , __func__, fault->addr, fault->error_code); WARN_ON_ONCE(fault->is_tdp); r = FNAME(walk_addr)(&walker, vcpu, fault->addr, fault->error_code & ~PFERR_RSVD_MASK); if (!r) { pgprintk("%s: guest page fault\n" , __func__); if (!fault->prefetch) kvm_inject_emulated_page_fault(vcpu, &walker.fault); return RET_PF_RETRY; } fault->gfn = walker.gfn; fault->max_level = walker.level; fault->slot = kvm_vcpu_gfn_to_memslot(vcpu, fault->gfn); if (page_fault_handle_page_track(vcpu, fault)) { shadow_page_table_clear_flood(vcpu, fault->addr); return RET_PF_EMULATE; } r = mmu_topup_memory_caches(vcpu, true ); if (r) return r; r = kvm_faultin_pfn(vcpu, fault, walker.pte_access); if (r != RET_PF_CONTINUE) return r; .... }
在硬件MMU中,Table walk单元负责遍历页表,这里函数walk_addr就相当于硬件MMu中Table walk,负责遍历guest页表。 异常处理函数首先调用这个函数遍历guess页表,尝试取出GPA ,见14行代码,遍历完后,把具体信息保存在walker中。
感觉写的注释非常精髓
1 2 3 4 5 6 static int FNAME (walk_addr_generic) (struct guest_walker *walker, struct kvm_vcpu *vcpu, struct kvm_mmu *mmu, gpa_t addr, u64 access)
如果返回0,说明没有建立映射,进行guest的缺页处理,注入异常,guest去建立GVA到GPA的映射。见20行。
进入到kvm_inject_emulated_page_fault
x86.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void kvm_inject_emulated_page_fault (struct kvm_vcpu *vcpu, struct x86_exception *fault) { struct kvm_mmu *fault_mmu ; WARN_ON_ONCE(fault->vector != PF_VECTOR); fault_mmu = fault->nested_page_fault ? vcpu->arch.mmu : vcpu->arch.walk_mmu; if ((fault->error_code & PFERR_PRESENT_MASK) && !(fault->error_code & PFERR_RSVD_MASK)) kvm_mmu_invalidate_addr(vcpu, fault_mmu, fault->address, KVM_MMU_ROOT_CURRENT); fault_mmu->inject_page_fault(vcpu, fault); } EXPORT_SYMBOL_GPL(kvm_inject_emulated_page_fault);
会调用 inject_page_fault, 对应的函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void kvm_inject_page_fault (struct kvm_vcpu *vcpu, struct x86_exception *fault) { ++vcpu->stat.pf_guest; if (is_guest_mode(vcpu) && fault->async_page_fault) kvm_queue_exception_vmexit(vcpu, PF_VECTOR, true , fault->error_code, true , fault->address); else kvm_queue_exception_e_p(vcpu, PF_VECTOR, fault->error_code, fault->address); }
GPA-HPA 映射 建立映射后往后走,来到下一个重要函数
kvm_faultin_pfn这个函数用来处理虚拟地址映射到宿主机的物理地址
mmu.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static int kvm_faultin_pfn (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, unsigned int access) { int ret; fault->mmu_seq = vcpu->kvm->mmu_invalidate_seq; smp_rmb(); ret = __kvm_faultin_pfn(vcpu, fault); if (ret != RET_PF_CONTINUE) return ret; if (unlikely(is_error_pfn(fault->pfn))) return kvm_handle_error_pfn(vcpu, fault); if (unlikely(!fault->slot)) return kvm_handle_noslot_fault(vcpu, fault, access); return RET_PF_CONTINUE; }
这其中主要调用__kvm_faultin_pfn完成实际映射工作
1 2 3 4 5 6 7 8 9 10 11 12 static int __kvm_faultin_pfn(struct kvm_vcpu *vcpu, struct kvm_page_fault *fault){ struct kvm_memory_slot *slot = bool async; ..... async = false ; fault->pfn = __gfn_to_pfn_memslot(slot, fault->gfn, false , false , &async, fault->write, &fault->map_writable, &fault->hva); ...... }
而这里,最关键的是__gfn_to_pfn_memslot,通过这个函数拿到pfn
影子页表填充 映射和填充是两回事?
for_each_shadow_entry用来迭代不同页表级别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static int FNAME (fetch) (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault, struct guest_walker *gw) { ..... for_each_shadow_entry(vcpu, fault->addr, it) { gfn_t table_gfn; clear_sp_write_flooding_count(it.sptep); if (it.level == gw->level) break ; table_gfn = gw->table_gfn[it.level - 2 ]; access = gw->pt_access[it.level - 2 ]; sp = kvm_mmu_get_child_sp(vcpu, it.sptep, table_gfn, false , access); if (sp != ERR_PTR(-EEXIST)) { ............. if (FNAME(gpte_changed)(vcpu, gw, it.level - 1 )) goto out_gpte_changed; if (sp != ERR_PTR(-EEXIST)) link_shadow_page(vcpu, it.sptep, sp); if (fault->write && table_gfn == fault->gfn) fault->write_fault_to_shadow_pgtable = true ; ..... ret = mmu_set_spte(vcpu, fault->slot, it.sptep, gw->pte_access, base_gfn, fault->pfn, fault); ..... }
kvm_mmu_get_child_sp
1 2 3 4 5 6 7 8 9 10 11 12 13 static struct kvm_mmu_page *kvm_mmu_get_child_sp (struct kvm_vcpu *vcpu, u64 *sptep, gfn_t gfn, bool direct, unsigned int access) { union kvm_mmu_page_role role ; if (is_shadow_present_pte(*sptep) && !is_large_pte(*sptep)) return ERR_PTR(-EEXIST); role = kvm_mmu_child_role(sptep, direct, access); return kvm_mmu_get_shadow_page(vcpu, gfn, role); }
kvm_mmu_get_shadow_page来创建/查找
1 2 3 4 5 6 7 8 9 10 11 12 static struct kvm_mmu_page *kvm_mmu_get_shadow_page (struct kvm_vcpu *vcpu, gfn_t gfn, union kvm_mmu_page_role role) { struct shadow_page_caches caches = .page_header_cache = &vcpu->arch.mmu_page_header_cache, .shadow_page_cache = &vcpu->arch.mmu_shadow_page_cache, .shadowed_info_cache = &vcpu->arch.mmu_shadowed_info_cache, }; return __kvm_mmu_get_shadow_page(vcpu->kvm, vcpu, &caches, gfn, role); }
__kvm_mmu_get_shadow_page 最终的查找/创建影子页表页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static struct kvm_mmu_page *__kvm_mmu_get_shadow_page (struct kvm *kvm , struct kvm_vcpu *vcpu , struct shadow_page_caches *caches , gfn_t gfn , union kvm_mmu_page_role role ) { struct hlist_head *sp_list ; struct kvm_mmu_page *sp ; bool created = false ; sp_list = &kvm->arch.mmu_page_hash[kvm_page_table_hashfn(gfn)]; sp = kvm_mmu_find_shadow_page(kvm, vcpu, gfn, sp_list, role); if (!sp) { created = true ; sp = kvm_mmu_alloc_shadow_page(kvm, caches, gfn, sp_list, role); } trace_kvm_mmu_get_page(sp, created); return sp; }
遍历到最后一级页表,相应的表项不存在,就需要位GPA申请物理页面、填充页表项了
set_pte寻找空闲的物理页,填充页表项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int mmu_set_spte (struct kvm_vcpu *vcpu, struct kvm_memory_slot *slot, u64 *sptep, unsigned int pte_access, gfn_t gfn, kvm_pfn_t pfn, struct kvm_page_fault *fault) { struct kvm_mmu_page *sp = int level = sp->role.level; ........ if (is_shadow_present_pte(*sptep)) ...... wrprot = make_spte(vcpu, sp, slot, pte_access, gfn, pfn, *sptep, prefetch, true , host_writable, &spte); ... }
make_spte 生成新的页表项
建立好之后的寻址 每次访问cr3都会触发异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static int handle_cr (struct kvm_vcpu *vcpu) { unsigned long exit_qualification, val; int cr; int reg; int err; int ret; exit_qualification = vmx_get_exit_qual(vcpu); cr = exit_qualification & 15 ; reg = (exit_qualification >> 8 ) & 15 ; switch ((exit_qualification >> 4 ) & 3 ) { case 0 : val = kvm_register_read(vcpu, reg); trace_kvm_cr_write(cr, val); switch (cr) { case 0 : err = handle_set_cr0(vcpu, val); return kvm_complete_insn_gp(vcpu, err); case 3 : WARN_ON_ONCE(enable_unrestricted_guest); err = kvm_set_cr3(vcpu, val); return kvm_complete_insn_gp(vcpu, err); ..........
不知道kvm_register_read读取的cr3是否存储着影子页表的地址,是的话逻辑就比较简单了,设置cr3为影子页表的地址,然后就拿到了地址映射,进行后续内存操作??
1 2 3 4 int kvm_set_cr3 (struct kvm_vcpu *vcpu, unsigned long cr3) { ..... vcpu->arch.cr3 = cr3;
二、EPT 简而言之:MMU完成GVA到GPA的映射(kvm不捕获异常了,guest自己处理),EPT完成GPA到HPA的映射 . 引入了EPT violation异常处理EPT的缺页
具体而言:当Guest内部发生缺页异常时,CPU不再切换到Host模式了,而是由Guest自身的缺页异常处理函数处理。当地址从GVA翻译到GPA后,GPA在硬件内部从MMU流转到了EPT。 如果EPT页表中存在GPA到HPA的映射,则EPA最终获取了GPA对应的HPA,将HPA送上地址总线。如果EPT中尚未建立GPA到HPA的映射,则CPU抛出EPT异常,CPU从Guest模式切换到Host模式 ,KVM中的EPT异常处理函数负责寻找空闲物理页面,建立EPT表中GPA到HPA的映射。
VMX在VMCS中定义了一个字段 Extended-Page-Table Pointer,KVM可以将EPT页表的位置写入这个字段,这样当CPU进入Guest模式时,就可以从这个字段读取EPT页表的位置。
EPT页表的设置 vmx.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static void vmx_load_mmu_pgd (struct kvm_vcpu *vcpu, hpa_t root_hpa, int root_level) { struct kvm *kvm = bool update_guest_cr3 = true ; unsigned long guest_cr3; u64 eptp; if (enable_ept) { eptp = construct_eptp(vcpu, root_hpa, root_level); vmcs_write64(EPT_POINTER, eptp); hv_track_root_tdp(vcpu, root_hpa); if (!enable_unrestricted_guest && !is_paging(vcpu)) guest_cr3 = to_kvm_vmx(kvm)->ept_identity_map_addr; else if (kvm_register_is_dirty(vcpu, VCPU_EXREG_CR3)) guest_cr3 = vcpu->arch.cr3; else update_guest_cr3 = false ; vmx_ept_load_pdptrs(vcpu); } else { guest_cr3 = root_hpa | kvm_get_active_pcid(vcpu); } if (update_guest_cr3) vmcs_writel(GUEST_CR3, guest_cr3); }
通过construct_eptp构建ept,然后vmcs_write64写入vmcs,这里是将root_hpa作为了EPT的根页面,第18行,设置变量guest_cr3指向guest自己的页表,最后27行,把cr3的值写入VMCS字段,这样切入guest后,guest模式下的CPU的cr3寄存器就指向了自己的页表。
EPT页表的构建 / 缺页异常处理 (GPA-HPA) CPU需要查询EPT表来进行GPA-HPA的转换,初始情况下,guest cr3指向的地址的页表项都是空的,CPU触发EPT violation ,虚拟机产生退出,并且退出原因为EXIT_REASON_EPT_VIOLATION ,会调用handle_ept_violation 处理函数
vmx.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static int handle_ept_violation (struct kvm_vcpu *vcpu) { unsigned long exit_qualification; gpa_t gpa; u64 error_code; exit_qualification = vmx_get_exit_qual(vcpu); if (!(to_vmx(vcpu)->idt_vectoring_info & VECTORING_INFO_VALID_MASK) && enable_vnmi && (exit_qualification & INTR_INFO_UNBLOCK_NMI)) vmcs_set_bits(GUEST_INTERRUPTIBILITY_INFO, GUEST_INTR_STATE_NMI); gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS); ....... return kvm_mmu_page_fault(vcpu, gpa, error_code, NULL , 0 ); }
经过一系列检查和设置后进入kvm_mmu_page_fault处理函数,这里就检查了mmio这种错误,如果不是的话,会进入下一个处理函数kvm_mmu_do_page_fault
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int noinline kvm_mmu_page_fault (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u64 error_code, void *insn, int insn_len) { .... r = RET_PF_INVALID; if (unlikely(error_code & PFERR_RSVD_MASK)) { r = handle_mmio_page_fault(vcpu, cr2_or_gpa, direct); if (r == RET_PF_EMULATE) goto emulate; } if (r == RET_PF_INVALID) { r = kvm_mmu_do_page_fault(vcpu, cr2_or_gpa, lower_32_bits(error_code), false , &emulation_type); ..... } EXPORT_SYMBOL_GPL(kvm_mmu_page_fault);
kvm_mmu_do_page_fault
mmu_internal.h 这里会进入kvm_tdp_page_fault(上面的影子页表就进入else了)
1 2 3 4 5 6 7 8 9 10 11 12 13 static inline int kvm_mmu_do_page_fault (struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u32 err, bool prefetch, int *emulation_type) { ...... if (IS_ENABLED(CONFIG_RETPOLINE) && fault.is_tdp) r = kvm_tdp_page_fault(vcpu, &fault); else r = vcpu->arch.mmu->page_fault(vcpu, &fault); ..... }
kvm_tdp_page_fault, 目前还不是很了解tdp,但走这两条路都能到最后的地址映射
1 2 3 4 5 6 7 8 9 10 int kvm_tdp_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) { ..... #ifdef CONFIG_X86_64 if (tdp_mmu_enabled) return kvm_tdp_mmu_page_fault(vcpu, fault); #endif return direct_page_fault(vcpu, fault); }
kvm_tdp_mmu_page_fault中的kvm_faultin_pfn是GPA到HPA的重要函数
1 2 3 4 5 6 7 static int kvm_tdp_mmu_page_fault (struct kvm_vcpu *vcpu, struct kvm_page_fault *fault) { .. r = kvm_faultin_pfn(vcpu, fault, ACC_ALL); ... }
direct_page_fault的最后会走到direct_map函数,direct_map是EPT页表构建过程中的关键函数, 建立映射,感觉一些主体逻辑和 FNAME(fetch)有点像
三、TLB缓存 EPT:CPU使用TLB(Translation Lookaside Buffer)缓存线性虚拟地址到物理地址的映射,地址转换时CPU先根据GPA先查找TLB,如果未找到映射的HPA,将根据页表中的映射填充TLB,再进行地址转换。
影子页表方案:不同Guest的vCPU切换执行时需要刷新TLB,严重影响了内存访问效率。因此,Intel引入了VPID(Virtual-Processor Identifier)技术在硬件上为TLB增加一个标志,每个TLB表项与一个VPID关联,唯一对应一个vCPU,当vCPU切换时可根据VPID找到并保留已有的TLB表项,减少TLB刷新。
VPID VPID是一种硬件级的对TLB资源管理的优化。通过在硬件上为每个TLB项增加一个标志,来标识不同的虚拟处理器地址空间,从而区分开VMM以及不同虚拟机的不同处理器的TLB。避免了每次切换都使得TLB全部失效。
VT-x 通过在VMCS中增加两个域来支持VPID,一个是VMCS中的enable VPID域,该域决定是否开启VPID功能。第二个是VPID域,用于标识VMCS对应的TLB。VMM本身也需要一个VPID,VT-x规定虚拟处理器标志0被指定用于VMM自身。
capabilities.h中有一个关于内存两大特性的结构体
1 2 3 4 struct vmx_capability { u32 ept; u32 vpid; };
会在hardware_setup函数中设置相关特性是否开启
1 2 3 4 5 static __init int hardware_setup (void ) { if (!cpu_has_vmx_vpid() || !cpu_has_vmx_invvpid() || !(cpu_has_vmx_invvpid_single() || cpu_has_vmx_invvpid_global())) enable_vpid = 0 ;
剩下的事好像就没软件什么事了,归硬件去操作
四、参考 https://www.cnblogs.com/LoyenWang/p/13943005.html 不过这个是arm的
https://mp.weixin.qq.com/s/fLSSbtPjx29Gg-IJfgnbZw
https://zhuanlan.zhihu.com/p/108425561 TLB原理
http://www.xiongfuli.com/%E8%99%9A%E6%8B%9F%E5%8C%96/2013-06/KVM-Implementation.html
https://luohao-brian.gitbooks.io/interrupt-virtualization/content/kvmzhi-nei-cun-xu-ni531628-kvm-mmu-virtualization.html
https://cloud.tencent.com/developer/article/1975756
https://royhunter.github.io/2014/06/18/KVM-EPT/

 wechat
wechat alipay
alipay




