
论文阅读笔记1-USENIX-MundoFuzz_Hypervisor_Fuzzing
虚拟化安全的pre,其实是自己第一次讲顶会论文…觉得一篇论文的工作量和细节还是蛮大的,也学到了挺多,在之后应该多读和多分析论文. 这篇文章是设计了一个fuzz工具,针对hypervisor,改进了fuzz中常用的两种方法,并且设计出了一套从开始收集数据,数据处理到后面fuzz的系统,在代码覆盖率方面比现有最好的hypervisor工具提高了5%左右,并且发现了40个bug,其中qemu通过了9个cve,其余还在申请中..
PS: 感觉工作量真的大…分析一篇都要很久,而且还没有太深入..更何况要去做(太菜了太菜了)
论文链接: https://www.usenix.org/conference/usenixsecurity22/presentation/myung
有作者的演讲视频和ppt,可以看一下
一. Introduction
这部分可以详细读一下,介绍了本文的大背景,现有的一些研究的不足,本文的主要贡献等.
二. 背景知识
2.1 hypervisor的外设输入空间
本文是针对hypervisor的外设部分进行fuzz,外设很好理解,就是虚拟出来的,比如鼠标键盘,硬盘,驱动等,这些物理外设,与之交互的话,都有一些特殊的协议和格式.
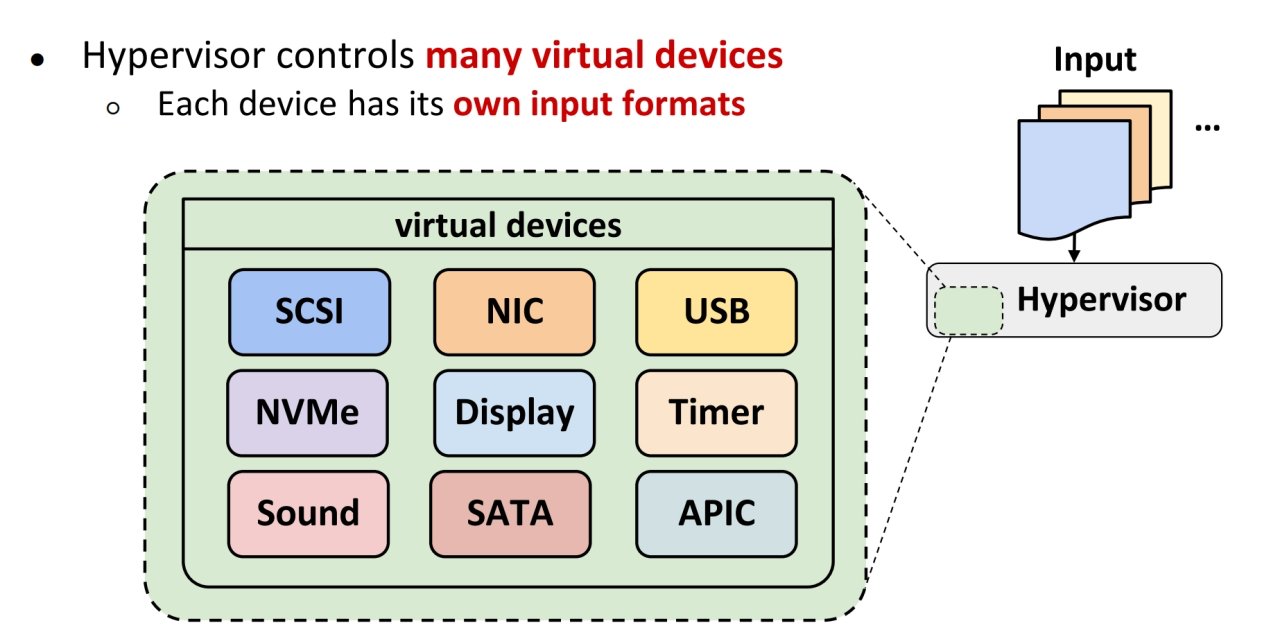
因为是虚拟出来的,和真实的设备不一样,所以不能直接访问,需要通过其他方法,常用的有三种
PIO(Programmed Input/Output)是一种最基本的输入/输出(I/O)通道,它将设备寄存器映射到一个独立的地址空间。这个地址空间只能通过特殊指令(in/out)访问。PIO的优点是简单,但它的局限是设备寄存器只能通过专用指令进行访问,这会带来一些限制。
MMIO(Memory-Mapped Input/Output)则将设备寄存器映射到内存地址的一个地址范围内,使得设备寄存器可以通过内存操作(例如加载或存储)访问。MMIO的优点是简化了设备访问的编程接口,但它的缺点是需要占用一部分内存地址空间。
DMA(Direct Memory Access)是一种直接内存访问技术,允许设备直接访问主机内存,而不需要CPU的干预。在DMA中,操作系统内核首先分配一块共享内存缓冲区,并将其地址告知虚拟设备。然后虚拟设备可以直接访问这个缓冲区以接收或返回数据。DMA的优点是可以减少CPU的开销,但它也需要特殊的硬件支持和一些额外的管理开销来确保安全和保护内存的一致性。
完成信号
虚拟设备通过io操作完成任务退回到空闲状态时,通过发送信号通知vm实例 可以通过硬件中断或专用设备寄存器来实现.介绍这个是因为在后面要捕获io交互的操作,可以通过这个信号判定一个操作结束.
2.1 fuzz
fuzz是一种常用的软件发现的方法.

2.2 现有研究不足
覆盖引导: VDF手动进行排除噪音, 并且要把外设单独提取进行测试
基于语法: NYX 手动编写语法规则
都未能实现自动化,需要耗费大量人力
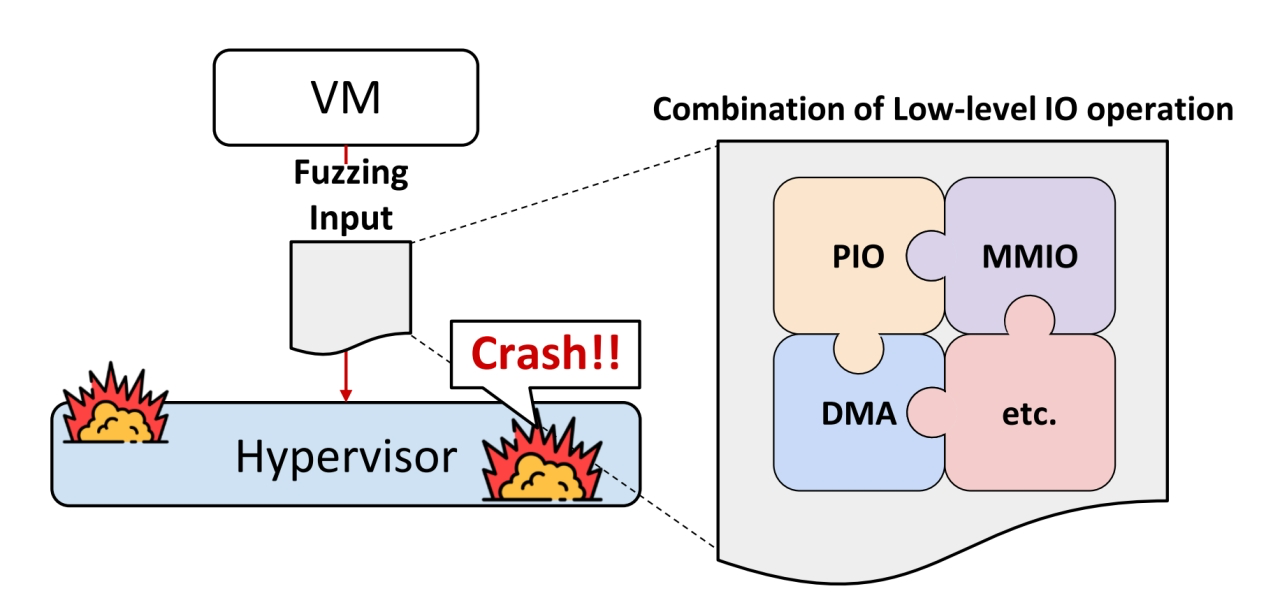
三. Hypervisor Fuzzing所面临的挑战
3.1 覆盖测量中的噪声-影响覆盖引导型测试
为什么会有噪声? 与它的固有属性有关,它是虚拟机管理程序,要虚拟化整个机器资源,所以它负责处理各种异步事件,尤其是终端和定时器事件,而这些事件和特定输入无关,就会导致输入混杂着噪音,从而输出也不一致.
假定是固定的输入能够得到固定的输出,这样的话才能够精确地去测量代码覆盖率等,噪声会严重影响测量.
3.2 解决方案
噪声不一定会在哪些代码分支里,但总应该是有不同的,取一个合适的测量次数值N,把所有测量结果取交集,就可以筛掉噪音.
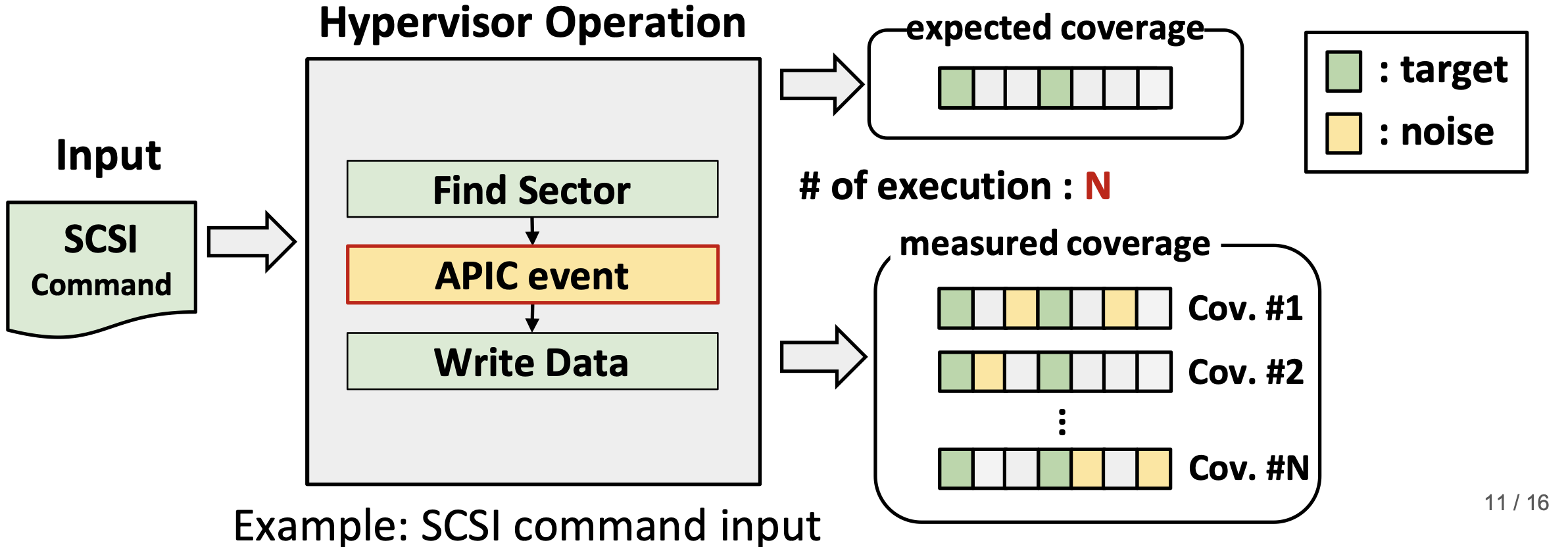
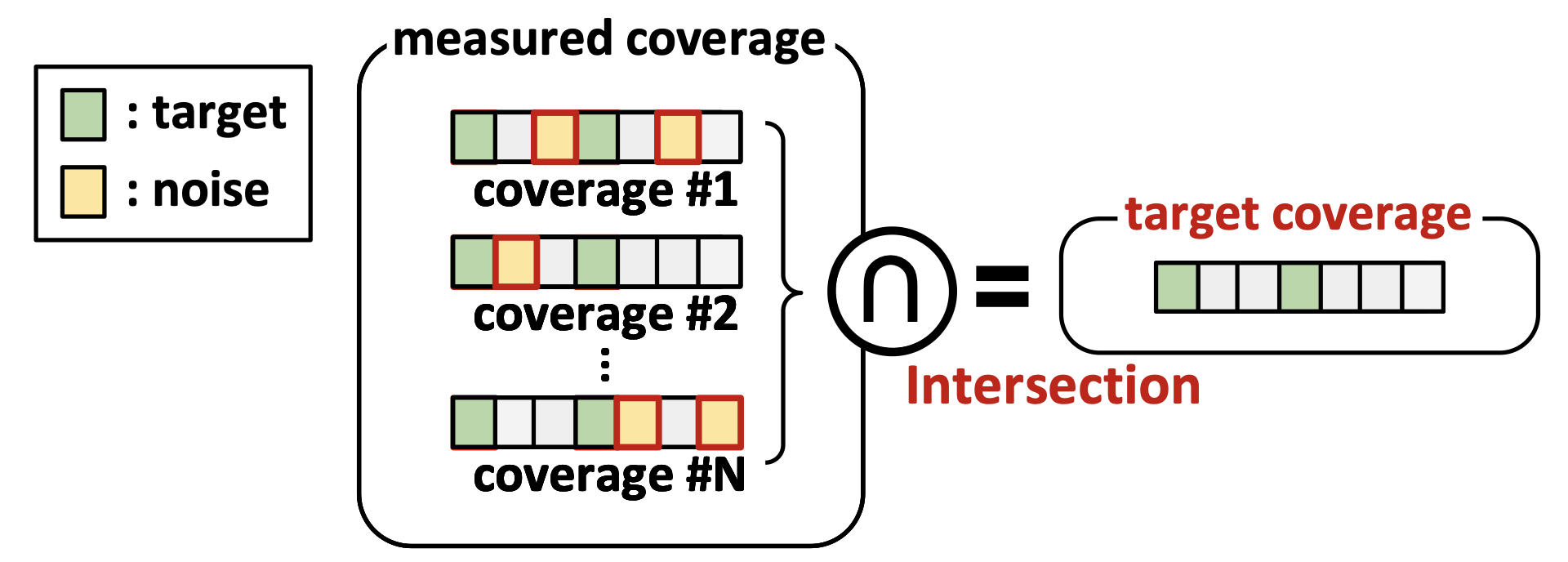
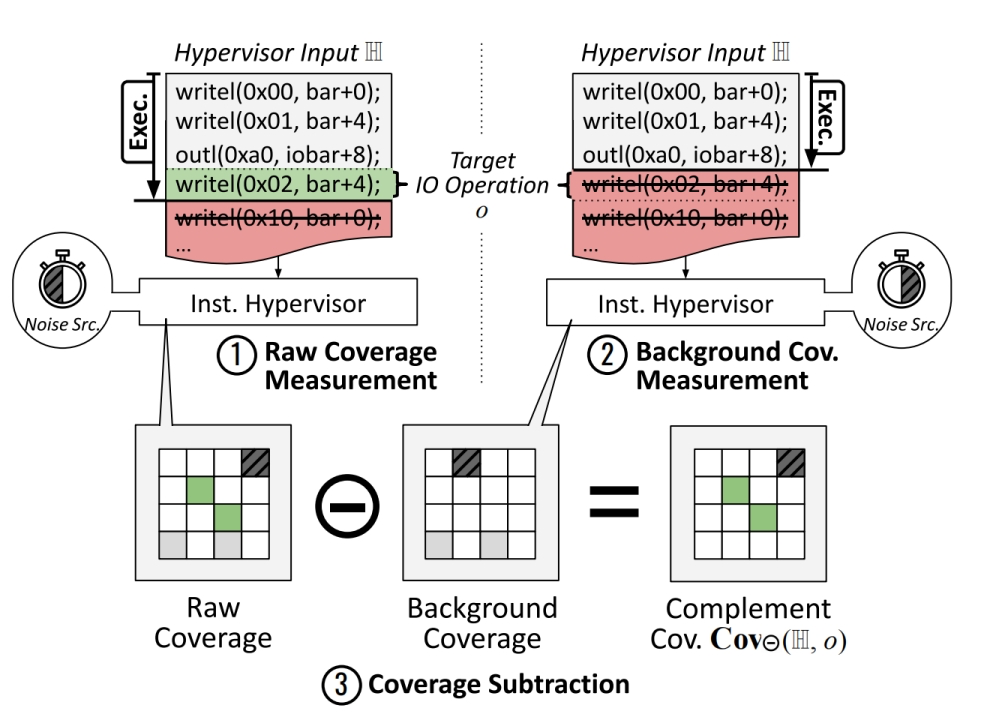
3.2.1 测量单条io指令所引起的代码覆盖变化
单条io指令执行后的结果其实是包含了它之前的所有指令的结果(包含一些必要的初始化操作),所以取两个完全一样的机器运行,左边的输入比右边多一条要测量代码覆盖变化的指令,这样左边的代码覆盖减去右边的代码覆盖,就得到了这一条指令的代码覆盖范围.
但还是有噪音的,通过之前所述的方法进行消除噪音即可.
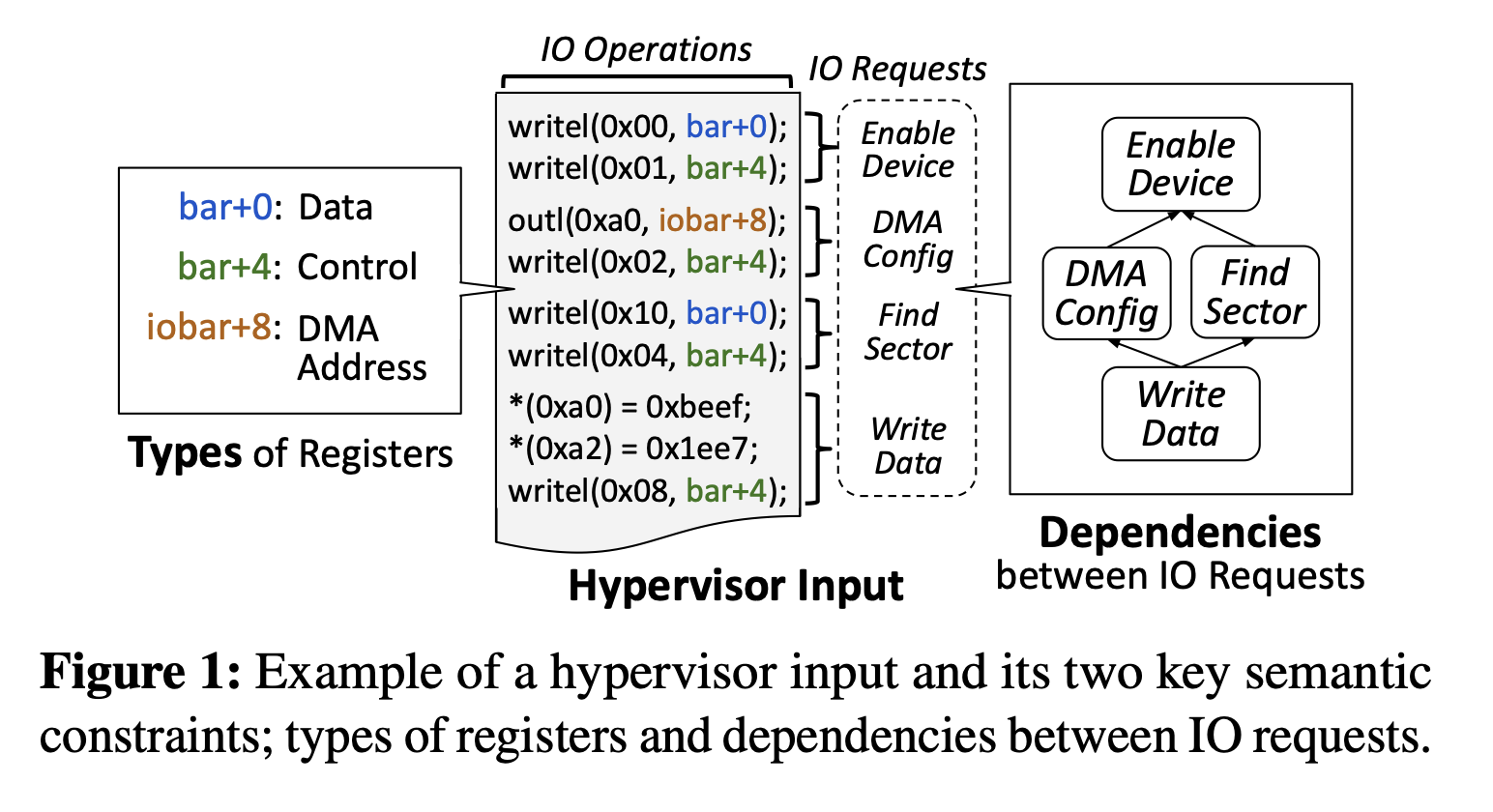
3.3 复杂的语义输入-影响语法感知型测试
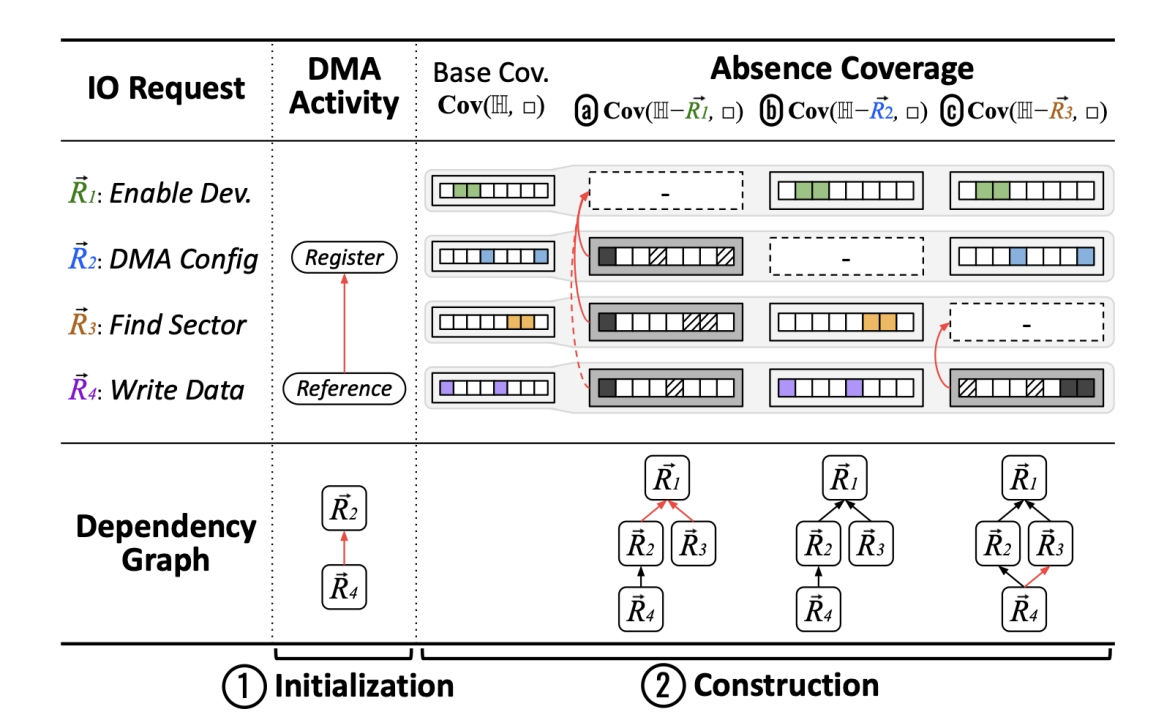
语义分了两种,一种是寄存器语义,如何识别控制寄存器和数据寄存器以及DMA寄存器,另外一种是依赖关系,操作是有前后的顺序的,比如先要找到扇区,再进行写入,这是逻辑依赖,还有一种是操作依赖,例如DMA,先要配置DMA的地址,然后再进行写入.
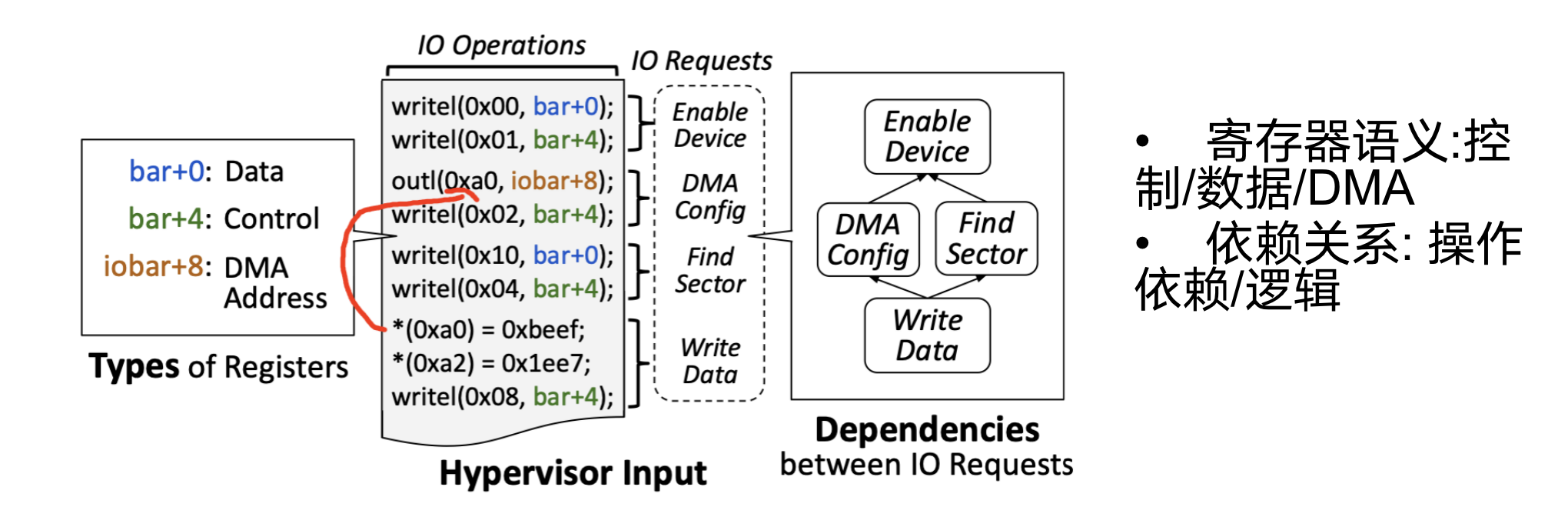
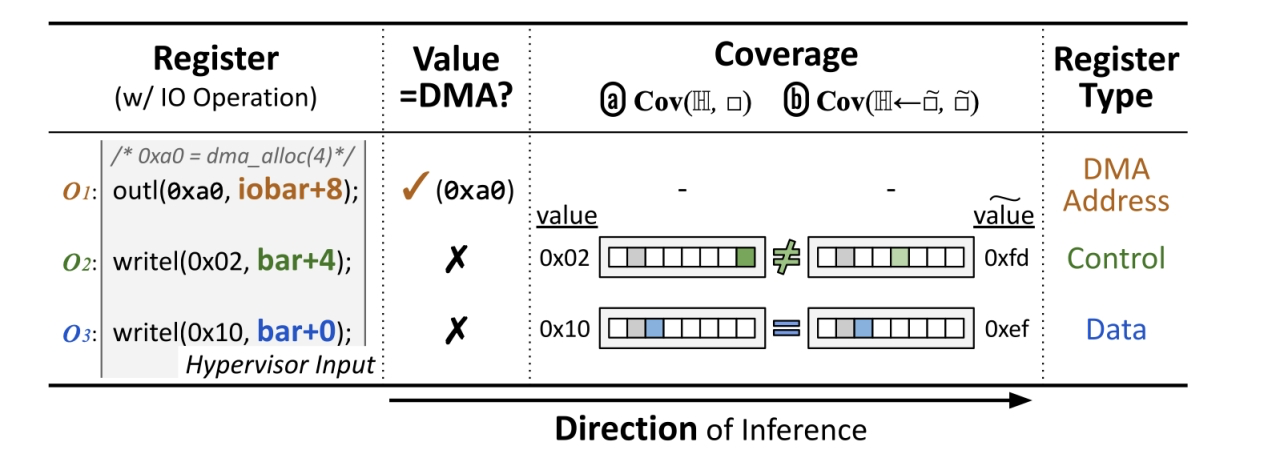
3.3.1 设备寄存器的语义
分了三类
1.控制寄存器
通过传递控制值来表明是需要哪个函数或操作指令
2.数据寄存器
传递参数等
3.DMA地址寄存器
传递DMA缓冲区的基地址
DMA地址寄存器可以直接进行识别,因为一开始就可以获取操作系统分配的DMA地址,只要检测是否在这个地址范围内,就可以确定是否是DMA寄存器
困难的是控制寄存器和数据寄存器的识别,如下图,不同的控制寄存器的值相当于调用不同的函数,数据寄存器也就是值



3.3.2 解决方案
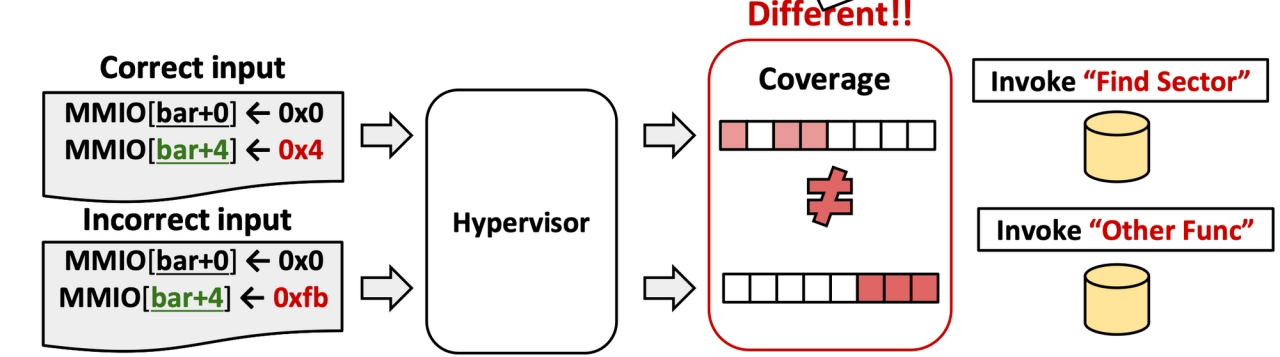
修改寄存器的值,看代码覆盖面是否改变,如果改变了,那说明应该是换了个函数,未改变的话就是变了数据
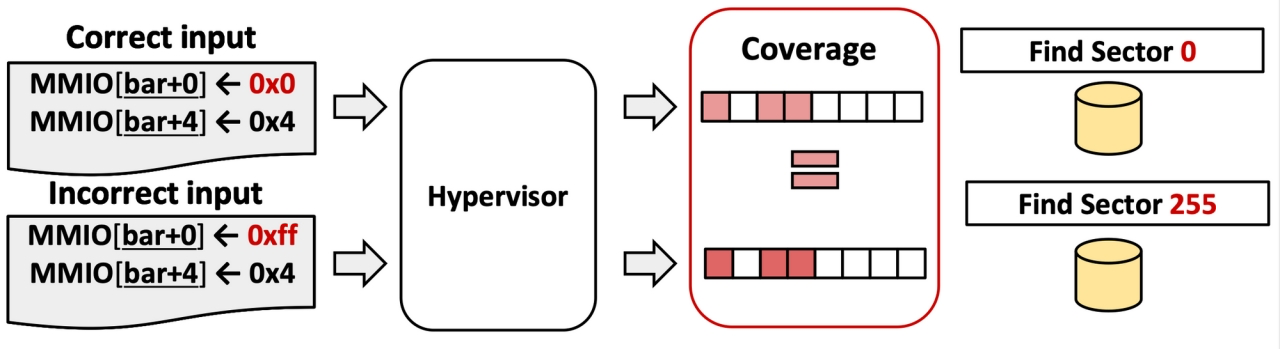
3.3.3 依赖关系
例如先要enable才能对设备进行操作, find sector之后才能write data
同样的,对于DMA的依赖也可以通过指令直接看出来
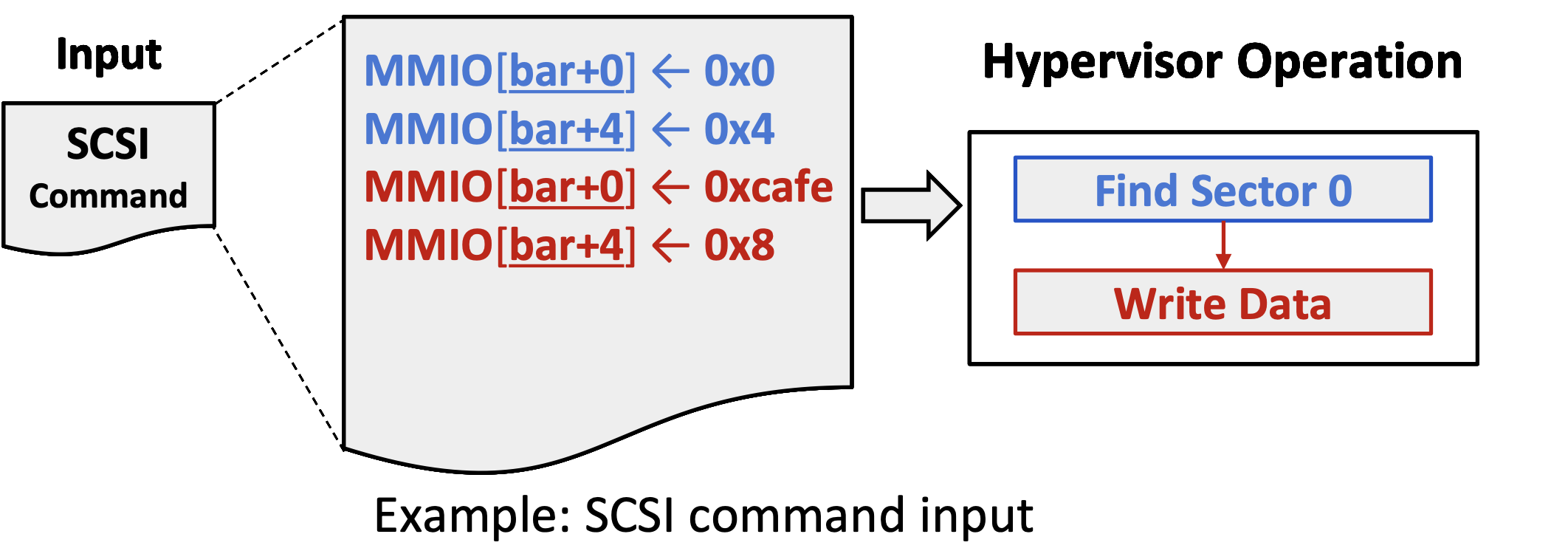
3.3.4 解决方案
针对语义:同样也是看代码覆盖,把前面的指令删除后,看是否影响后面的指令的代码覆盖面,如果影响的话,那应该就是有依赖关系
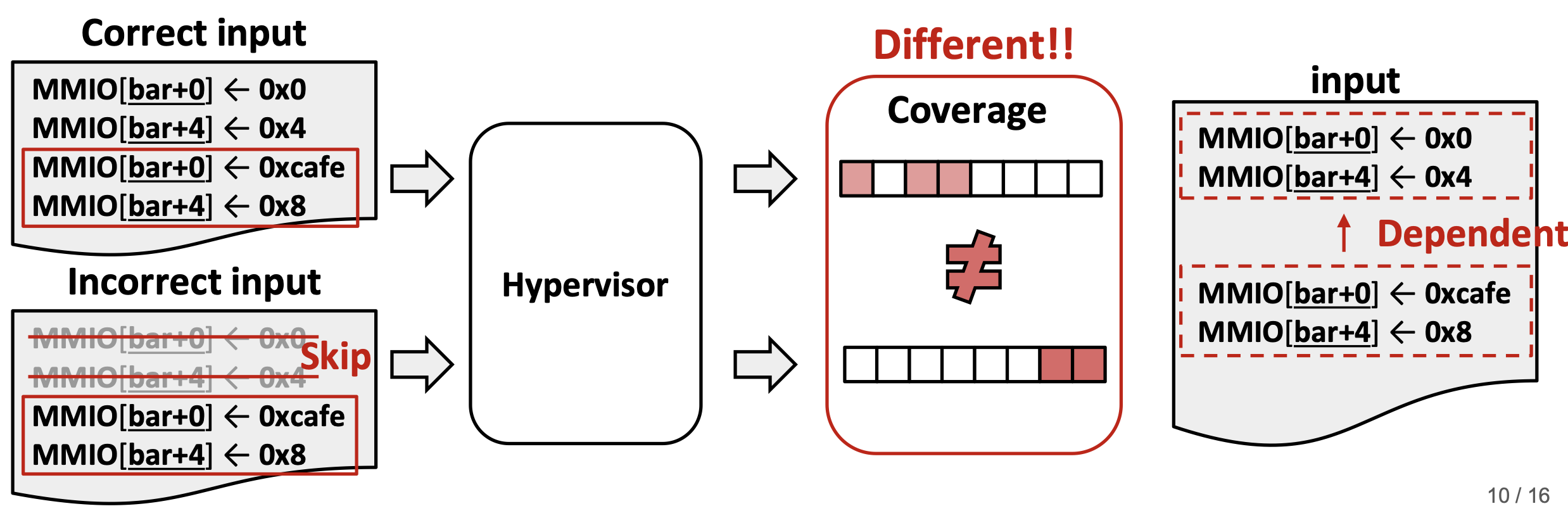
3.3.5 解决方案总结
3.4 依赖图生成
根据刚才的方法生成依赖图,方便后面用.. 懒得写了…
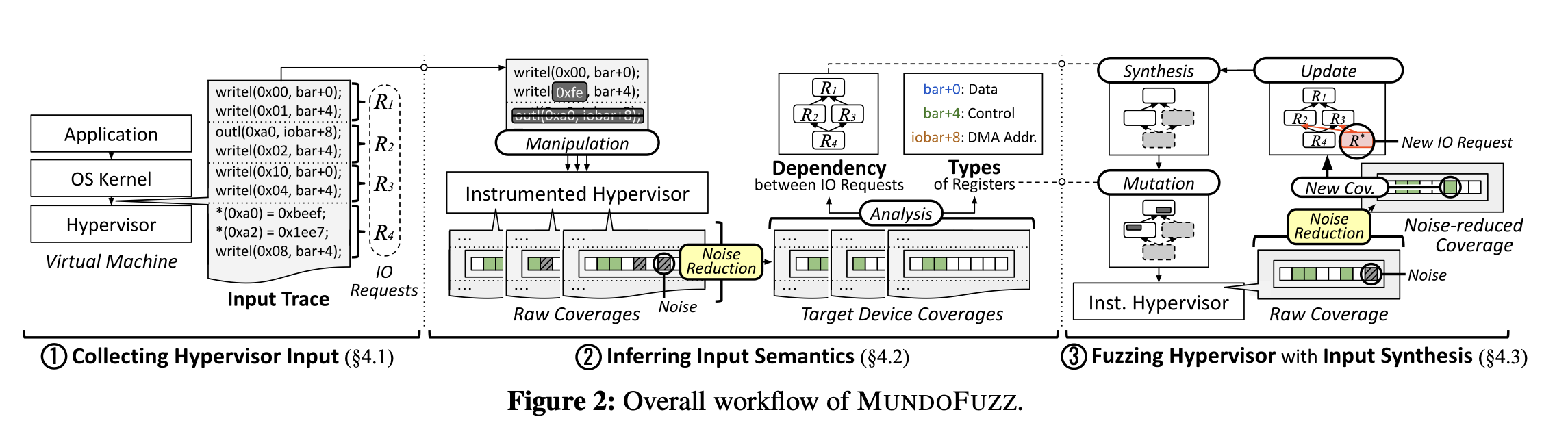
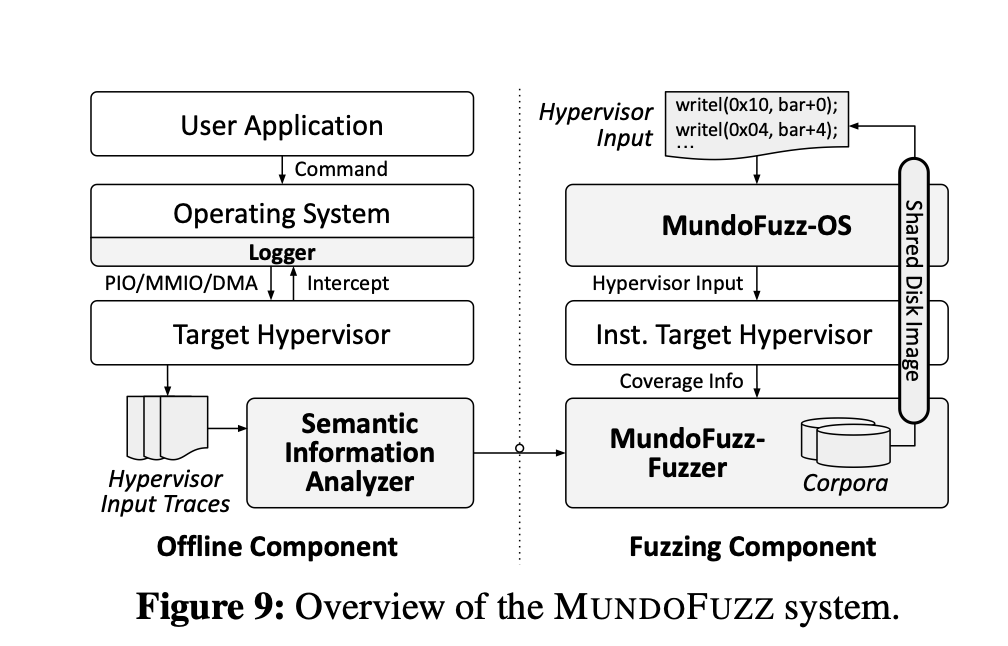
四. MUNDOFUZZ的设计
整体设计如下:主要分了三部分,一部分是收集数据,第二部分是刚才重点分析的数据处理(消除噪音和语义推断),第三部分是fuzz的过程.
4.1 收集Hypervisor输入数据
收集真实的数据,通过监测操作系统内核和设备之间的io交互,hook内核API,修改Linux内核,拦截请求开始-结束,进行切片
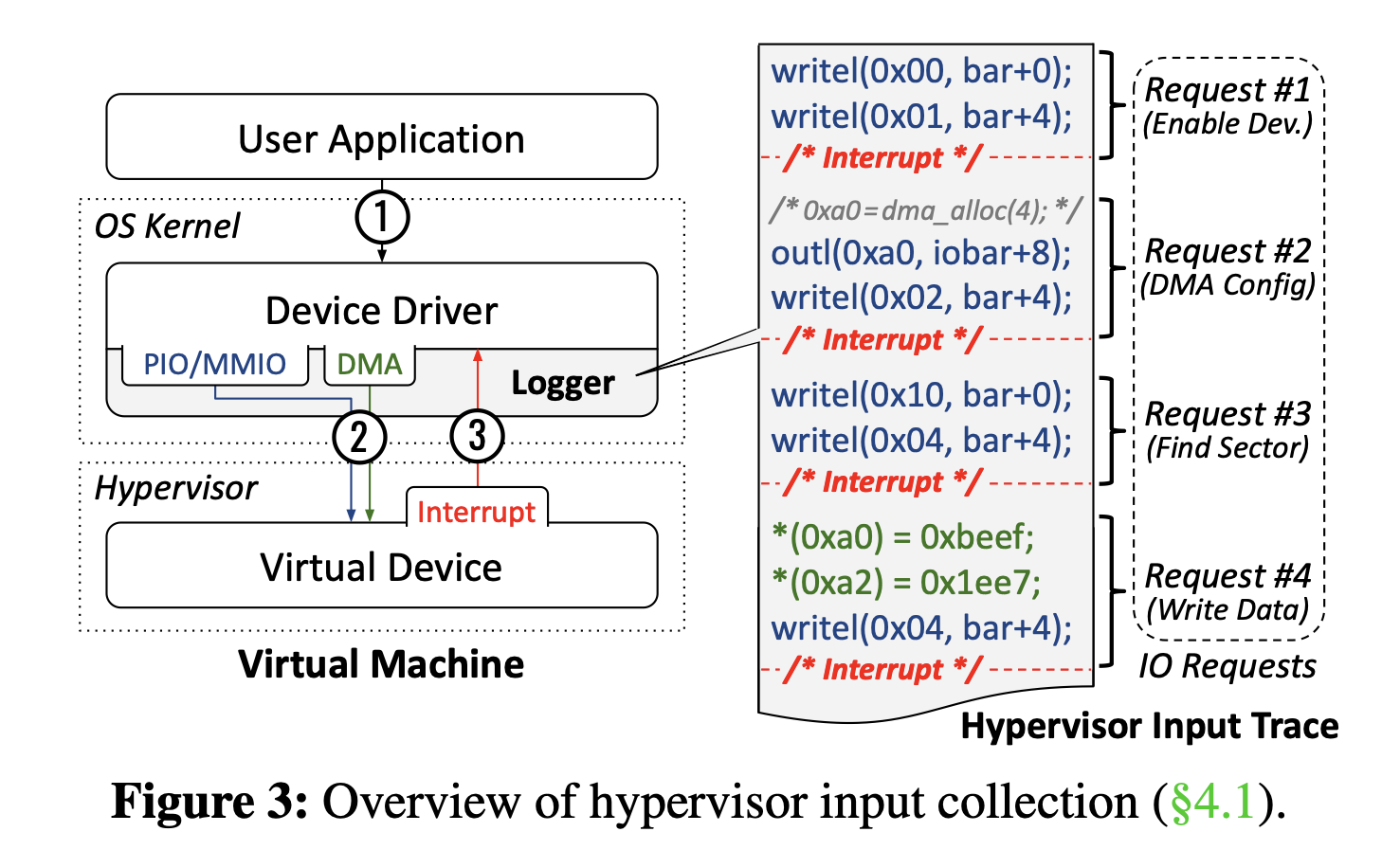
4.1.1 记录 PIO/MMIO 操作
记录对应的api即可
4.1.2 记录DMA操作
4.1.3 记录DMA缓冲区的分配
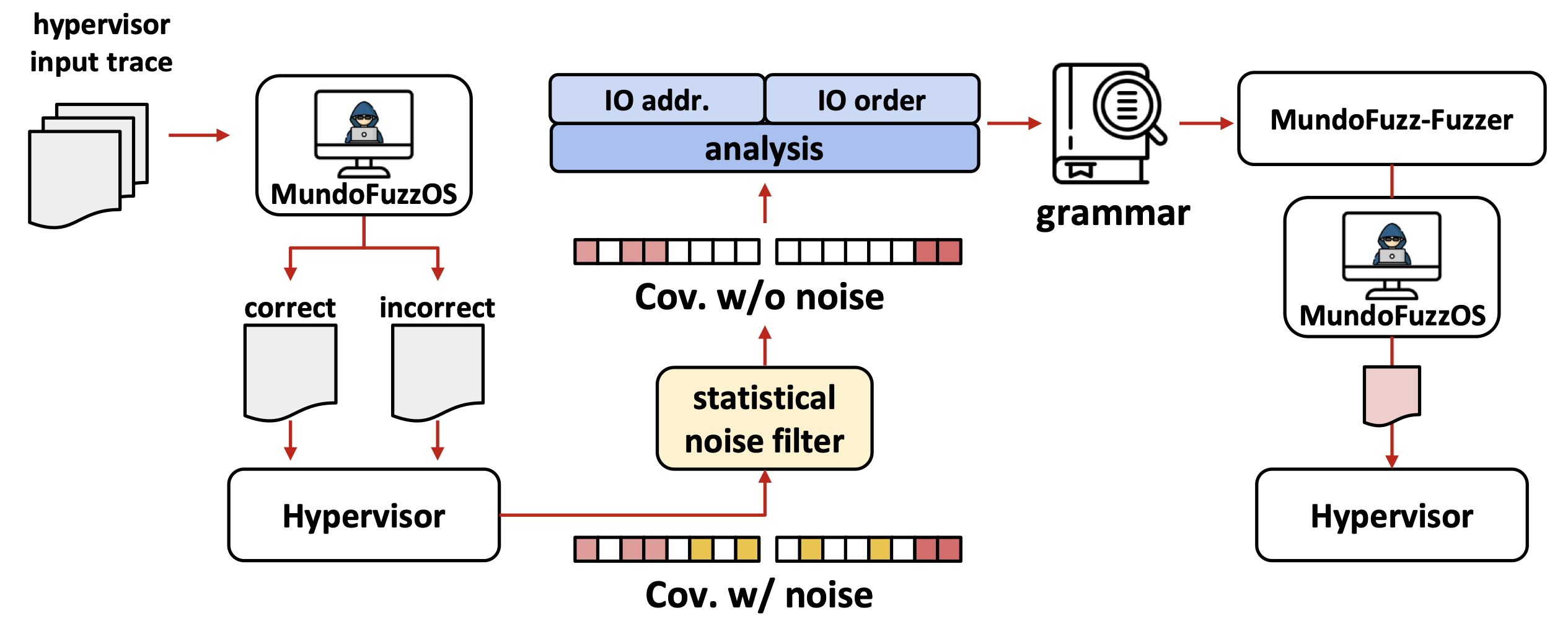
4.2 消除噪音和推断输入语义
略
4.3 合成输入,进行fuz
4.3.1 噪音覆盖去除
因为是在fuzz的时候进行的,所以需要考虑性能的问题, 对算法进行了优化
范围从单独的io操作提升到io请求(一组io操作),但比起输入仍然小很多(63比68574
使用不用任何寄存器的输入来查找噪声
4.3.2 fuzz和输入合成
语义的正确性是一方面,寄存器的值的正确性也很重要
工作流:生成,突变,更新

初始输入来源:1.预先储备的 2.根据依赖图和io请求语料库创建新的 5 5开
突变阶段: 根据寄存器种类进行相应改变 不同种类,改变频率不同 控制寄存器(代表新的io请求)
语料库更新: 根据覆盖反馈更新 新的覆盖范围 -> 输入语料库 如果属于新的io请求 -> io请求语料库,更新依赖图
五. 实际实现
log系统: Linux 5.8.0
fuzzer:基于AFL 2.57b
MUNDOFUZZ-OS:基于xv6实现,从fuzzer中得到输入,中继到目标
六. 评估
与目前最先进的hypervisor fuzz工具 hyper-cube和nyx进行对比
回答了三个问题
1.噪音消减技术是否提升了推断语义限制的准确性
2.在覆盖率上和最先进的两款工具比怎么样
3.它能发现未知的漏洞吗?
6.1 寄存器种类推断准确性
进行了一个对比实验,不用噪音消除和用了之后的.综合来说整体提高了50%,效果很明显
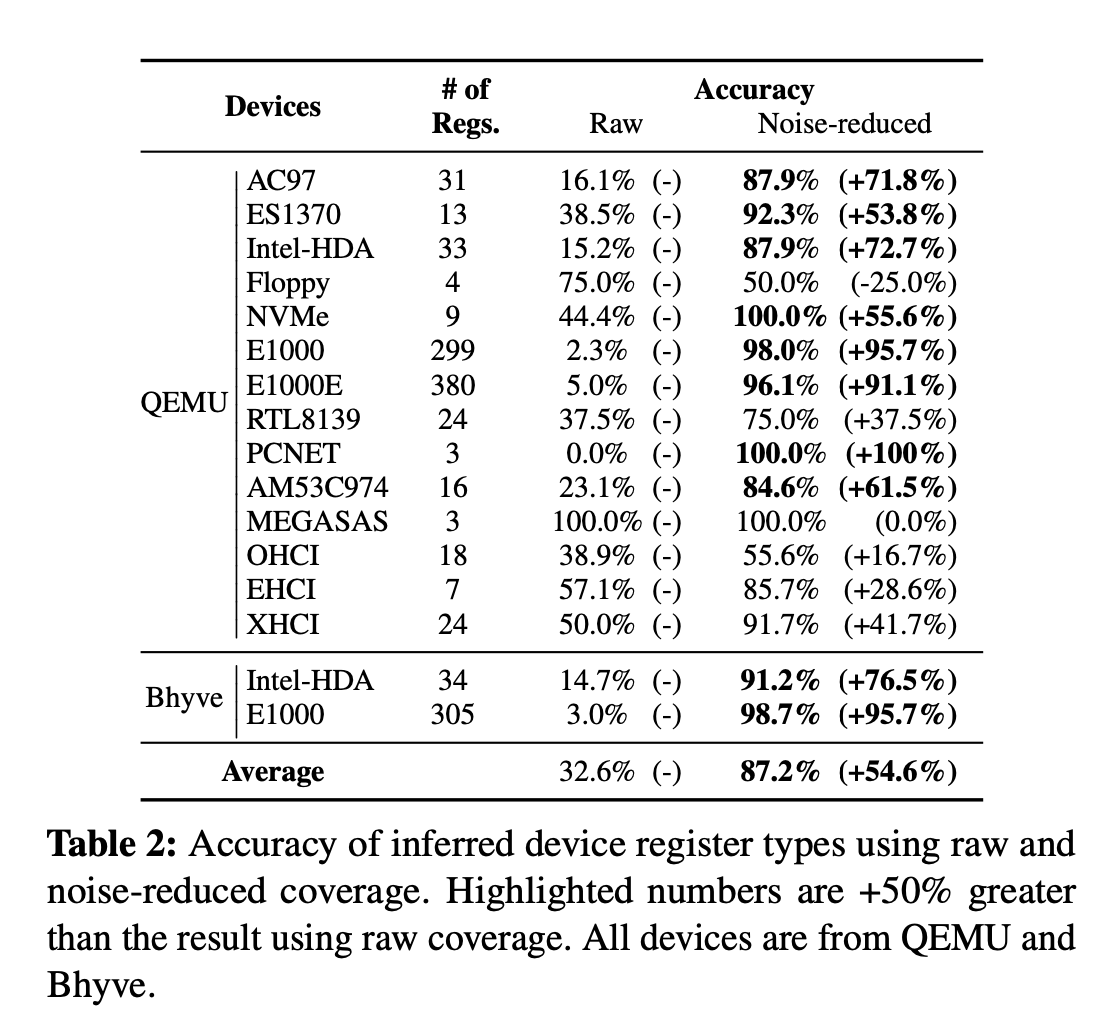
有一个是有问题的,降低了准确率,Floppy 因为它数据寄存器和命令寄存器复用了,但也好解决,混合类型进行推断即可
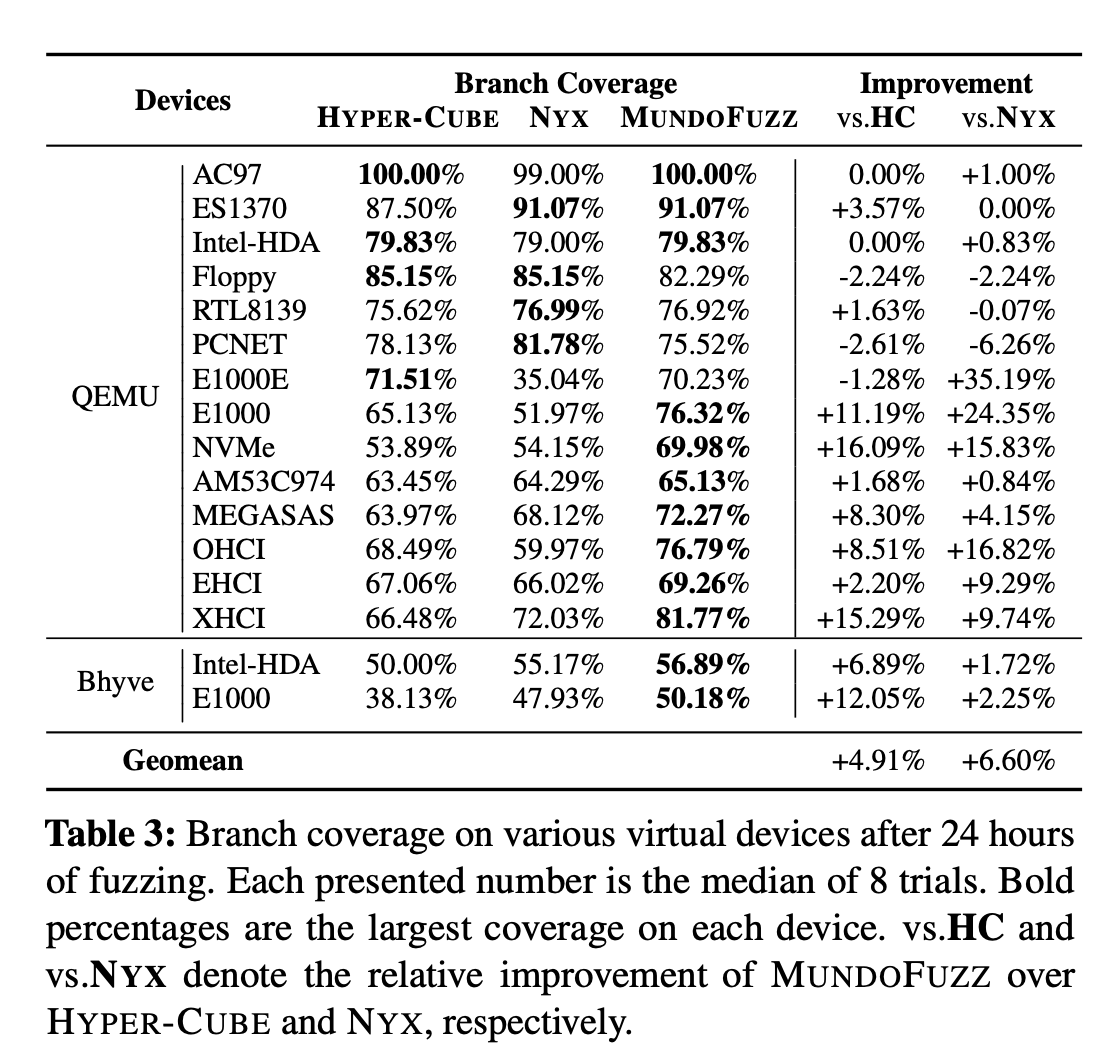
6.2 覆盖率对比
实验跑了24小时,重复了8次(评估指南),和最先进的hypervisor fuzz工具相比,提高了5%左右
6.3 新的漏洞

漏洞案例

七. 总结

 wechat
wechat alipay
alipay




